
End-to-end Testing for Cyber-Security Applications
June 15, 2023OCA and Kestrel at Black Hat 2023
August 8, 2023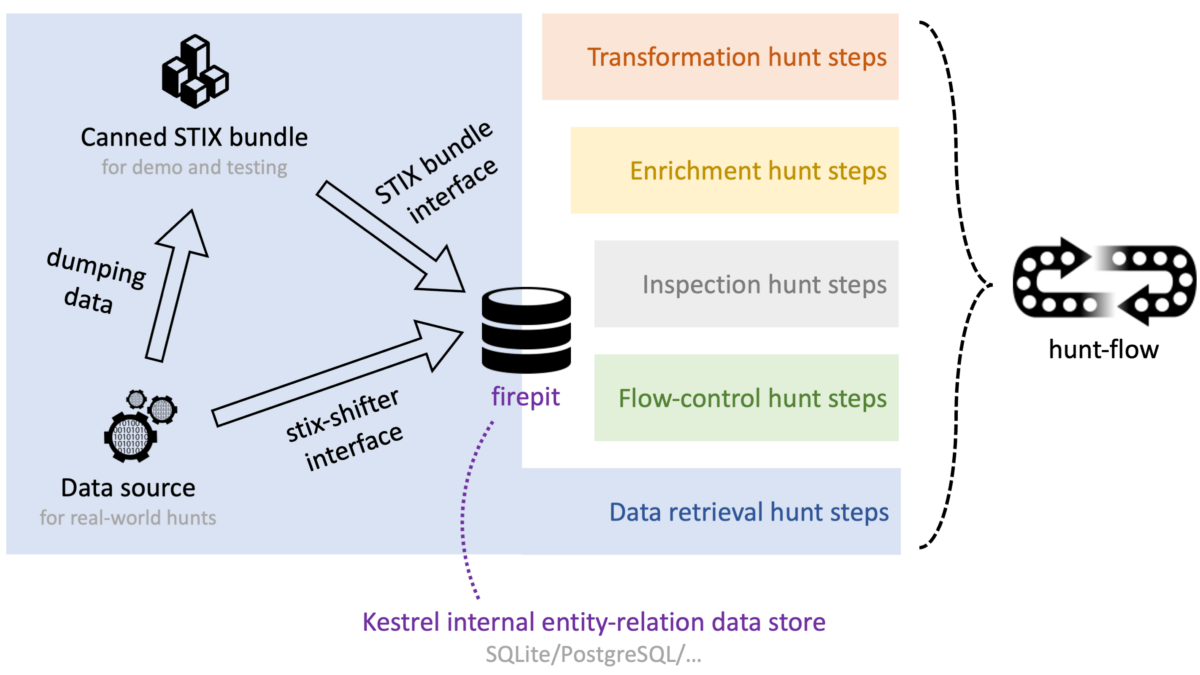
Kestrel provides a layer of abstraction to compose hunt-flows with standard hunt steps that run across many data sources and data types. This blogs overviews how data is retrieved, processed, and stored in Kestrel, and explains the 10x data retrieval performance improvement through Kestrel 1.5, 1.6, and 1.7.
Data Lifecycle Overview
Hunting is the procedure to find a string of needles (attack steps) in the haystack (gigantic monitored data pool). Among different hunt steps/commands in a hunt-flow (shown in Figure 1), the retrieval steps, e.g., GET, are the steps to pull data from data sources to Kestrel internal data store (firepit). During the execution of the retrieval steps, data is transmitted, translated, and ingested into the internal data store.
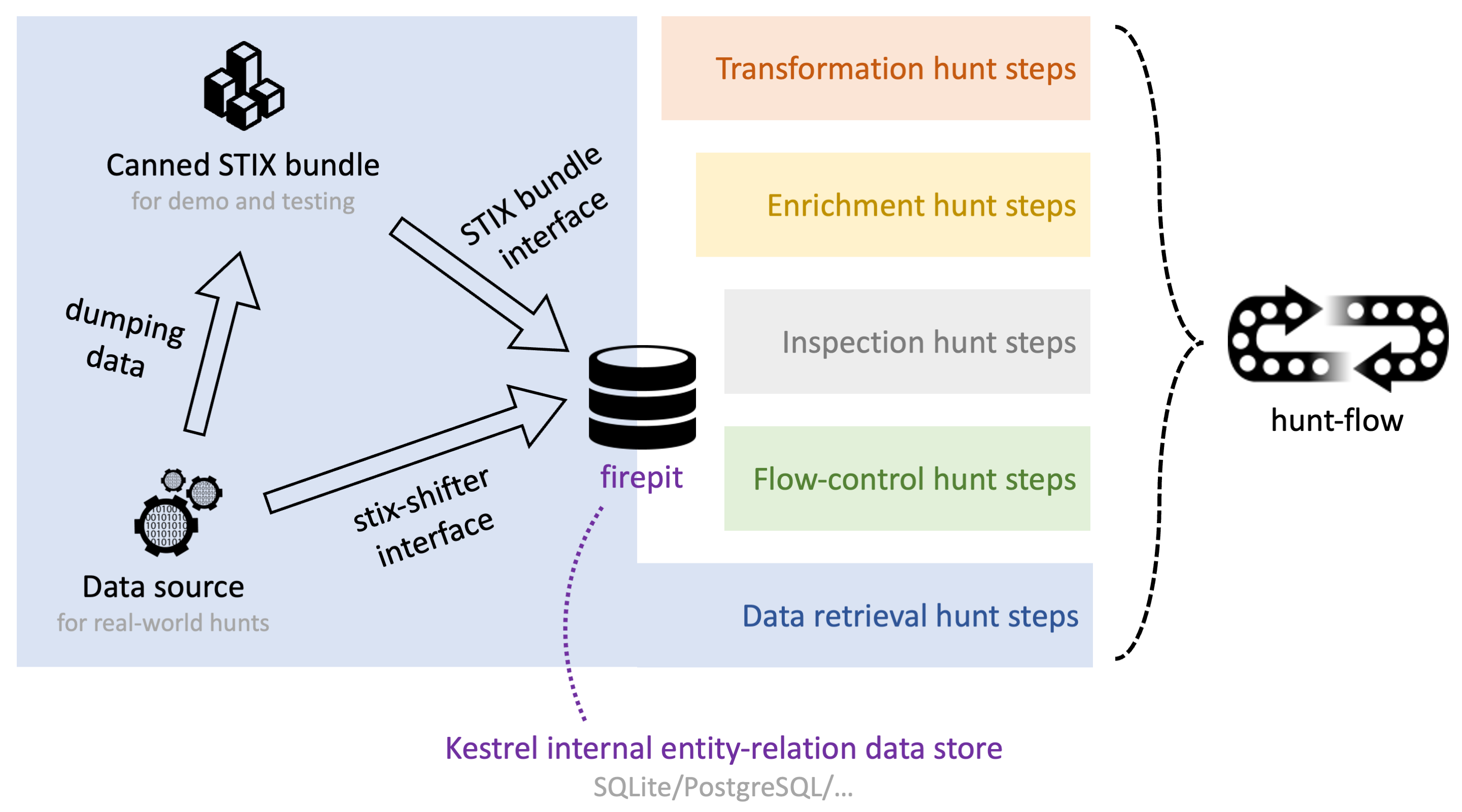
The Kestrel internal data store implements an entity-relation view of the data on top of relational database—each type of entity resides in one table, and the relations between entities reside in a separate table. Kestrel variables are realized as views of entity tables. Most hunt steps such as transformation and inspection are read-only or projection steps, except that retrieval and enrichment steps (Kestrel analytics) could write new rows/columns in the tables, or even create tables, e.g., new entities from retrieval.
Data Retrieval in Details
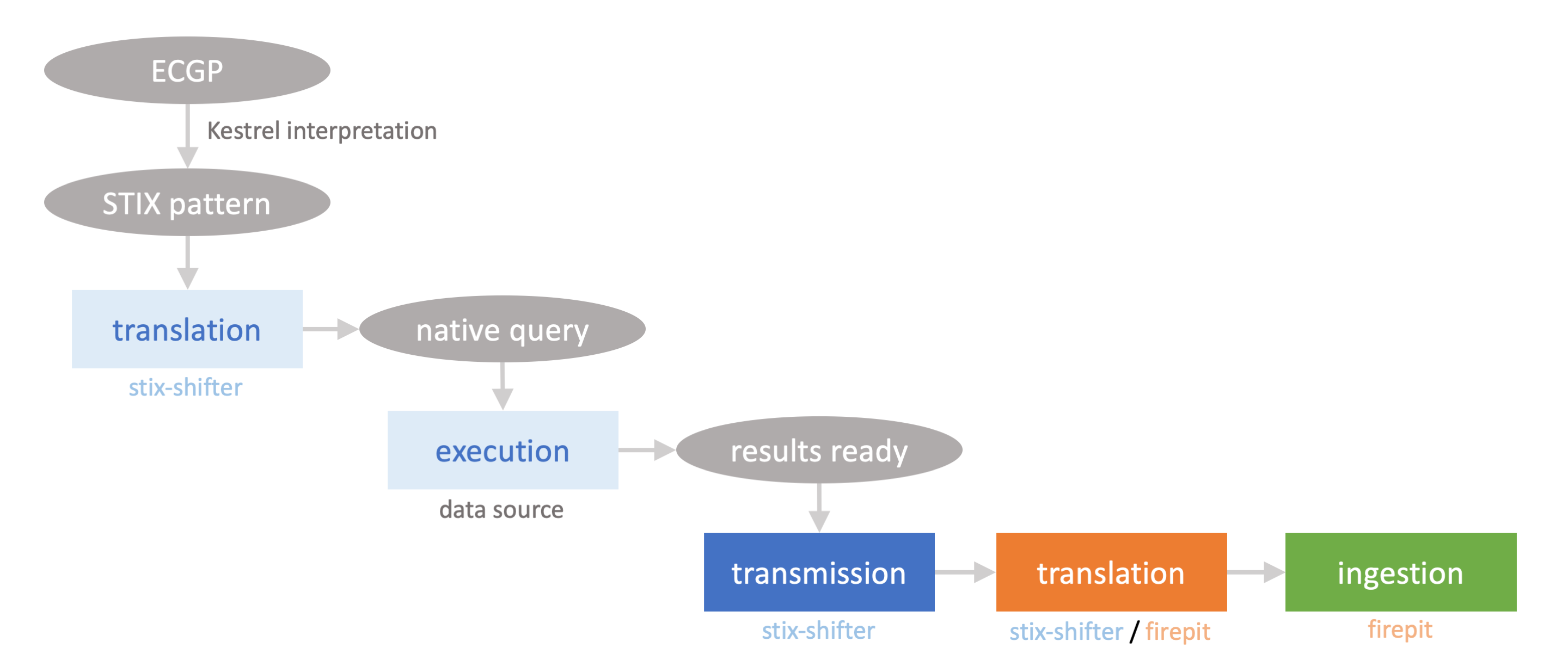
In real-world hunts, the data retrieval (Figure 2) is done through stix-shifter in the current Kestrel implementation, which enables hunters to connect to over 30 data sources (EDR, SIEM, log management systems, data lake, etc.). In Figure 2, most phases before the bottom three-box chain are lightweight and fast, while the most time-consuming phases are the three boxes at the bottom:
- Transmission: an I/O-bound phase transmitting data from a data source back to the Kestrel runtime, which could be running on the hunter’s laptop, on a hunting server on premise, or as a container in the cloud dedicated to hunt.
- Translation: a CPU-bound phase translating the raw data transmitted back from a data source to a standard/normalized format such as STIX observations (JSON in text) or a Pandas DataFrame (Python-native data structure; a faster alternative to JSON).
- Ingestion: an CPU-and-I/O-bound phase performing entity/relation recognition from the normalized data (translation results) and ingesting the entities and relations into the Kestrel internal data store (firepit).
Data Retrieval in Action
In theory, all phases of data retrieval should be executed in a sequence (shown in Figure 2). A simplified view is shown in Figure 3.

In reality, the first complication is pagination—big trunks of data may not be retrieved at once—many data sources such as Elasticsearch provide multi-page or multi-round retrieval for large data. For instance, Elasticsearch has a default page size of 10,000, and any amount of data larger than it should be fetched in multiple rounds with the search_after API.
In Kestrel 1.5.8, we add pagination support in the stix-shifter data source interface as illustrated in Figure 4.

In Kestrel 1.5.10, we realize fast translation (a firepit function) as an alternative to stix-shifter result translation (shown in Figure 5). Without fast translation, stix-shifter translates raw data from data sources to STIX in JSON (text) before ingestion. With fast translation enabled (configurable in stixshifter.yaml), the raw data is translated into Pandas DataFrame (Python-native data structure) to be more performant than JSON.
In Kestrel 1.6.0, we implement an async producer-consumer model between transmission and translation/ingestion to take advantage of the async support in stix-shifter v5. Unfortunately, this does not improve performance as expected since the CPU-bound translation (implemented in stix-shifter v5 async mode) always timeouts the I/O-bound transmission and restarts the transmission after the translation completes.
In Kestrel 1.7.0, we skip asyncio and move to multiprocessing to deal with both I/O-bound and CPU-bound phases. Figure 6 illustrates the data retrieval procedure with multi-process. The key operations are as follows:
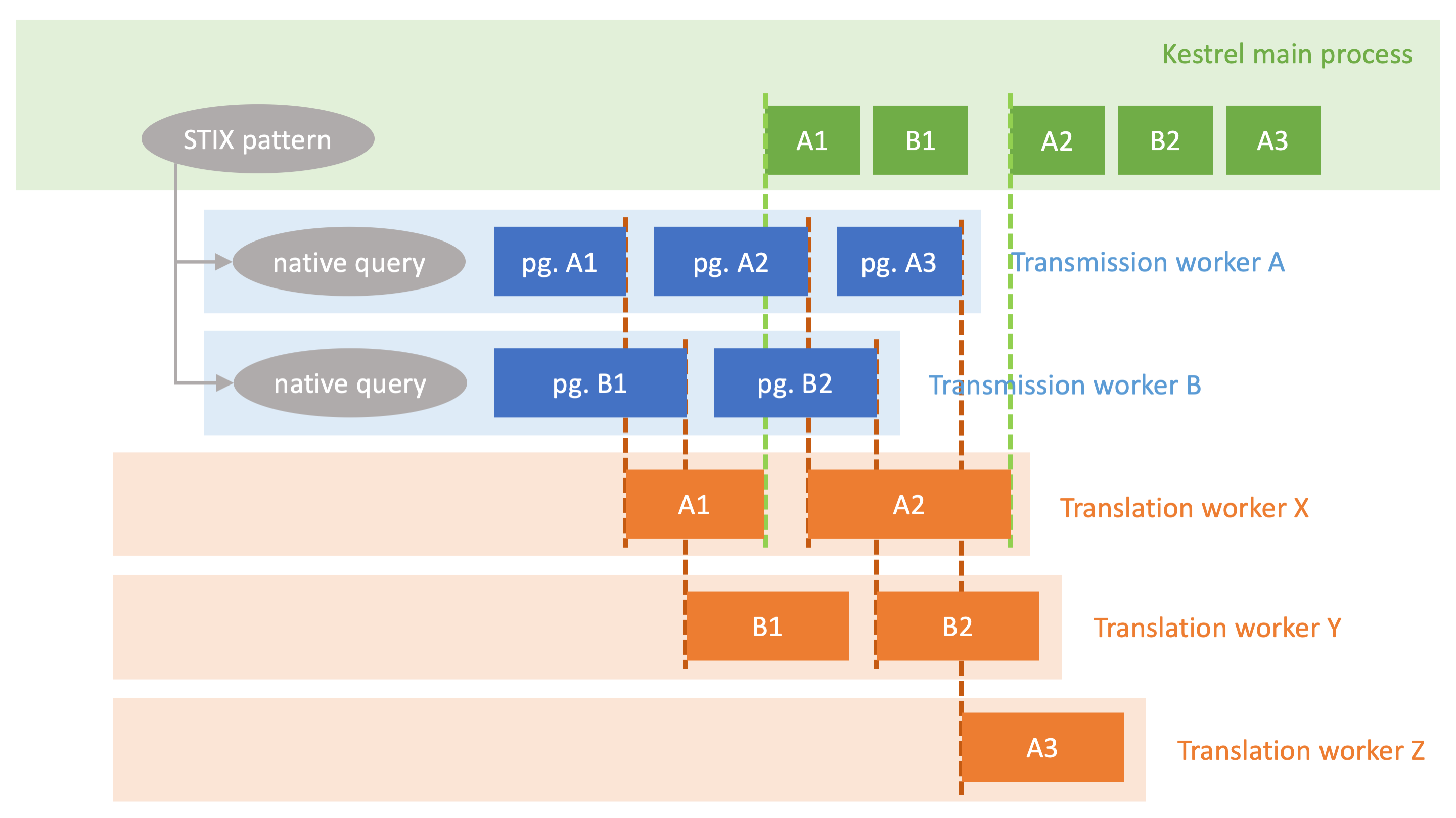
- Kestrel runtime establishes a pool of translation worker processes (the number of workers is configurable in
stixshifter.yaml). - Kestrel calls stix-shifter to translate a STIX pattern into
nnative data source queries. - Kestrel starts
ntransmission worker processes, each contacts the data source to execute one native query and retrieve results back. Multiple pages of the result of the same query, if exist, are retrieved back one by one by the same transmission worker. - Every page/batch of raw records (of transmission results) from every transmission worker is pushed to a transmission-translation queue when it arrives.
- Each batch of raw records in the transmission-translation queue is picked up by any free translation worker, translated using stix-shifter translation (JSON) or firepit fast translation (DataFrame), then pushed to the translation-ingestion queue.
- The Kestrel main process picks up any translation results from the translation-ingestion queue and ingests it into firepit. We intentionally serialize this ingestion phase in the main process to avoid problematic parallelism for SQLite (default firepit backend).
Performance Improvement Evaluation
We evaluate the performance improvement from Kestrel 1.5 to Kestrel 1.7 against three Elasticsearch data sources:
- Single-small-node: 4 vCore and 16 GB RAM VM.
- Single-large-node: 16 vCore and 64 GB RAM VM.
- Multi-node enterprise: an multi-node setup to support queries against data ingested from thousands to millions of log sources.
The single-hunt-step hunts we run against all three data sources are like the one below:
ips = GET ipv4-addr FROM stixshifter://datasourceX
WHERE value = '127.0.0.1'
LAST 24 HOURSDifferent IP addresses and time ranges against different data sources are used to retrieve 50k-150k records per hunt. The best run out of 5 is picked up to rule out slow network outliers and calculate throughputs in the table below:
| Kestrel 1.5 | Kestrel 1.7 | Speed | |
| Single-small-node Elasticsearch Testbed | 136 rec/sec | 1655 rec/sec | 12x |
| Single-large-node Elasticsearch Testbed | 221 rec/sec | 2399 rec/sec | 11x |
| Multi-node Enterprise Elasticsearch Testbed | 796 rec/sec | 3894 rec/sec | 5x |
After the series of performance upgrades, Kestrel v1.7 finally reaches a reasonably good design regarding data retrieval performance. Regarding wall-clock time, Kestrel v1.7 spends 1x-2x time in the entire data retrieval procedure (Figure 2) than the time spend on transmission alone. Since the transmission time is largely decided by the speed of the data source API, network bandwidth, and the serialized pagination procedure, there is limited space to improve.
Beyond data retrieval performance, the Kestrel team continues to work on improvements and upgrades to make Kestrel an enterprise-grade hunting tool. We will introduce new syntax in Kestrel v1.7.1 to enable hunting with super big data (sampled results without waiting for full return). Happy hunting and join us on slack!
Dr. Xiaokui Shu is a Senior Research Scientist at IBM Research and the Technical Steering Committee Chair of the Open Cybersecurity Alliance (OCA).


{kind=link}